papers
completed research projects; authors listed in alphabetical order
2025
-
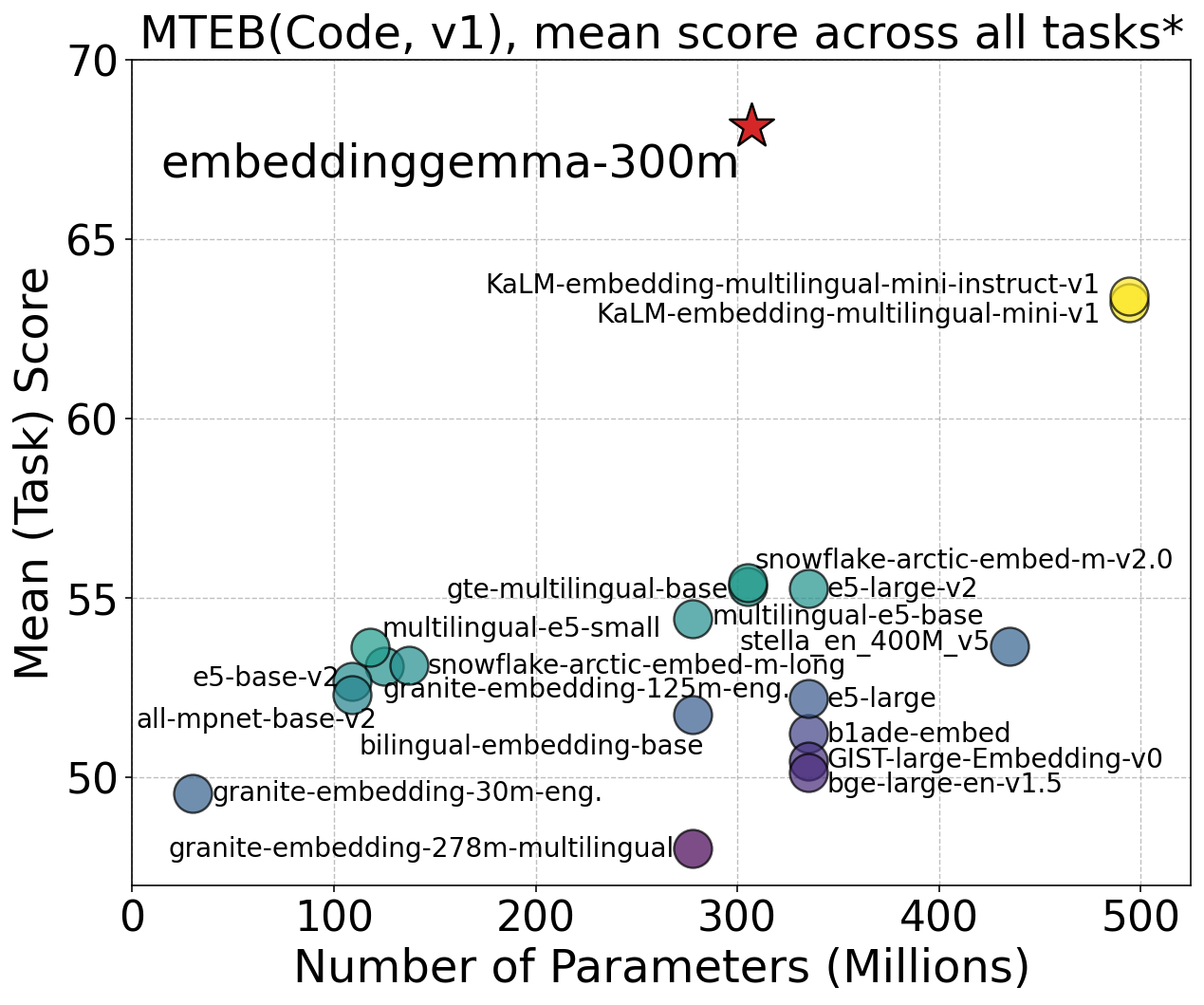 EmbeddingGemma: Powerful and Lightweight Text Representations2025
EmbeddingGemma: Powerful and Lightweight Text Representations2025We introduce EmbeddingGemma, a new lightweight, open text embedding model based on the Gemma 3 language model family. Our innovative training recipe strategically captures knowledge from larger models via encoder-decoder initialization and geometric embedding distillation. We improve model robustness and expressiveness with a spread-out regularizer, and ensure generalizability by merging checkpoints from varied, optimized mixtures. Evaluated on the Massive Text Embedding Benchmark (MTEB) across multilingual, English, and code domains, EmbeddingGemma (300M) achieves state-of-the-art results. Notably, it outperforms prior top models, both proprietary and open, with fewer than 500M parameters, and provides performance comparable to models double its size, offering an exceptional performance-to-cost ratio. Remarkably, this lead persists when quantizing model weights or truncating embedding outputs. This makes EmbeddingGemma particularly well-suited for low-latency and high-throughput use cases such as on-device applications. We provide ablation studies exploring our key design choices. We release EmbeddingGemma to the community to promote further research.
-
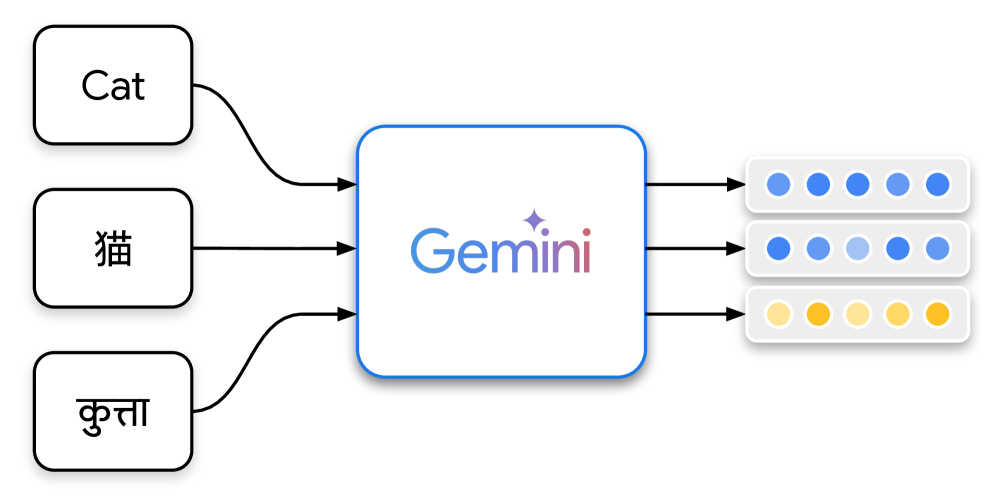 Gemini Embedding: Generalizable Embeddings from Gemini2025
Gemini Embedding: Generalizable Embeddings from Gemini2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
2023
-
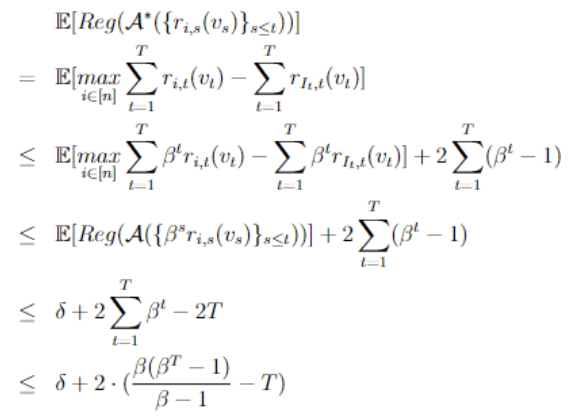 Selling to a Sophisticated No-Regret Buyer(advisor) Matt Weinberg, and Henrique Schechter Vera2023
Selling to a Sophisticated No-Regret Buyer(advisor) Matt Weinberg, and Henrique Schechter Vera2023Consider a repeated single item auction with a single buyer who has a value for the item randomly drawn from known distribution \(\mathcal{D}\) each round and bids according to an online learning algorithm. "Selling to a No-Regret Buyer" by Braverman et al. presents a strategy for the seller which, whenever the buyer bids according to a mean-based learning algorithm, extracts revenue that is arbitrarily close to the expected welfare. We extend these results to two settings where the bidder does not use a simple mean-based learning algorithm. First, we consider a bidder using a mean-based learning algorithm with recency bias, where the results of recent rounds are weighed more strongly. We show how much revenue the strategy yields as a function of the recency bias factor \(\beta\). Next, we consider a bidder using a k-switching learning algorithm, where what we define as a g-mean-based learning algorithm is given as options all "meta-strategies" which switch bids at most k times. We present a new strategy and show how much revenue it yields as a function of the g for which the learning algorithm is g-mean-based. In both settings, we also determine which parameter values allow the algorithm to be no-regret, and which yield revenue that is arbitrarily close to the welfare.
-
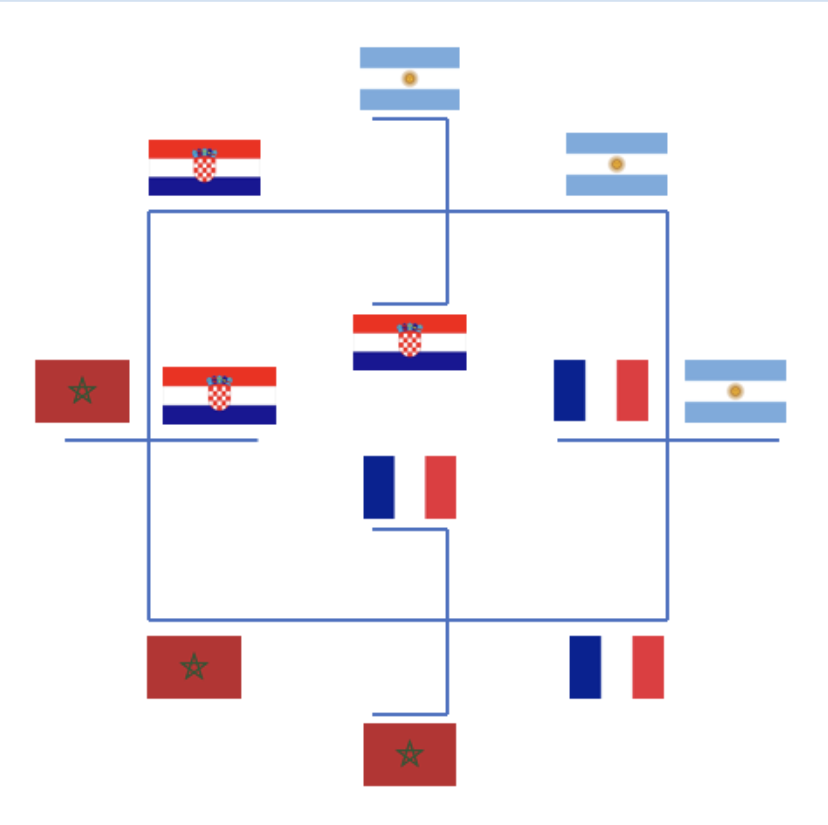 Extending Randomized Single Elimination Bracket to Multiple Prize Vectors2023
Extending Randomized Single Elimination Bracket to Multiple Prize Vectors2023We extend Randomized Single Elimination Bracket (RSEB) to tournaments with multiple prizes, creating two new tournament ranking rules: Randomized Complete Bracket (RCB) and Randomized Recursive Bracket (RRC). We prove various guarantees for manipulability and fairness under these rules. We first show that Randomized Complete Bracket is \(2\)-SNM-\(\frac{1}{2}\) and that both RCB and RRB are \(2\)-SNM-\(\frac{1}{3}\) for a subclass of prize vectors we call Binary Power-of-Two Prize Vectors. We then show that both rules are manipulable under the Borda vector presented in Dale et al. and that neither is cover-consistent or consistent under expectation. Finally, we provide a promising partial proof and empirical results towards showing that Randomized Complete Bracket is \(2\)-SNM-\(\frac{1}{3}\) for all prize vectors.
2022
-
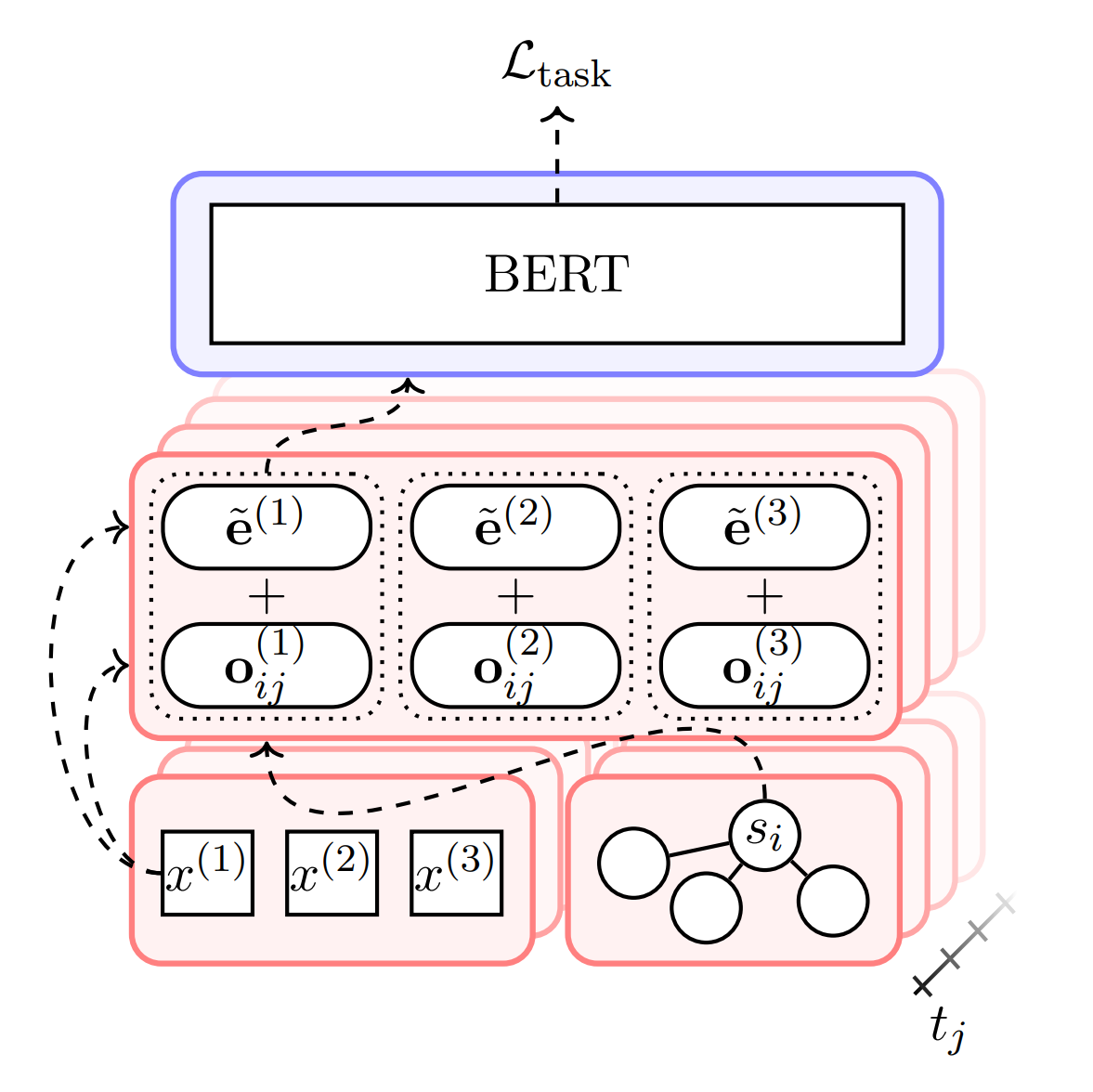 Exploring the Role of Contextualization in Dynamic Contextualized Word Embeddings2022
Exploring the Role of Contextualization in Dynamic Contextualized Word Embeddings2022Contemporary natural language tasks often use embeddings to extract information from text, especially for downstream applications. However, many embedding techniques are non-dynamic, meaning they do not capture extralinguistic context like time and social space. There are techniques that incorporate linguistic context (e.g., large language models like BERT and GPT), and dynamic embeddings can partially incorporate time and social space. We seek to replicate the findings of Hofmann et al., who propose Dynamic Contextualized Word Embeddings (DCWEs) as a technique for incorporating both linguistic and extralinguistic context by combining a pretrained contextual language model and a joint model of time and social space. After replicating their findings, we extend their work to a downstream sentiment analysis task in two ways: we consider multiple contextual models (e.g. GPT), and we explore the effect of a dynamic component on non-contextual embeddings created by traditional embeddings systems (e.g. Word2Vec). While we replicate the baseline findings, we find that the addition of DCWE is not beneficial for the other contextual embeddings. Furthermore, non-contextual embeddings performed substantially worse than the baseline.
-
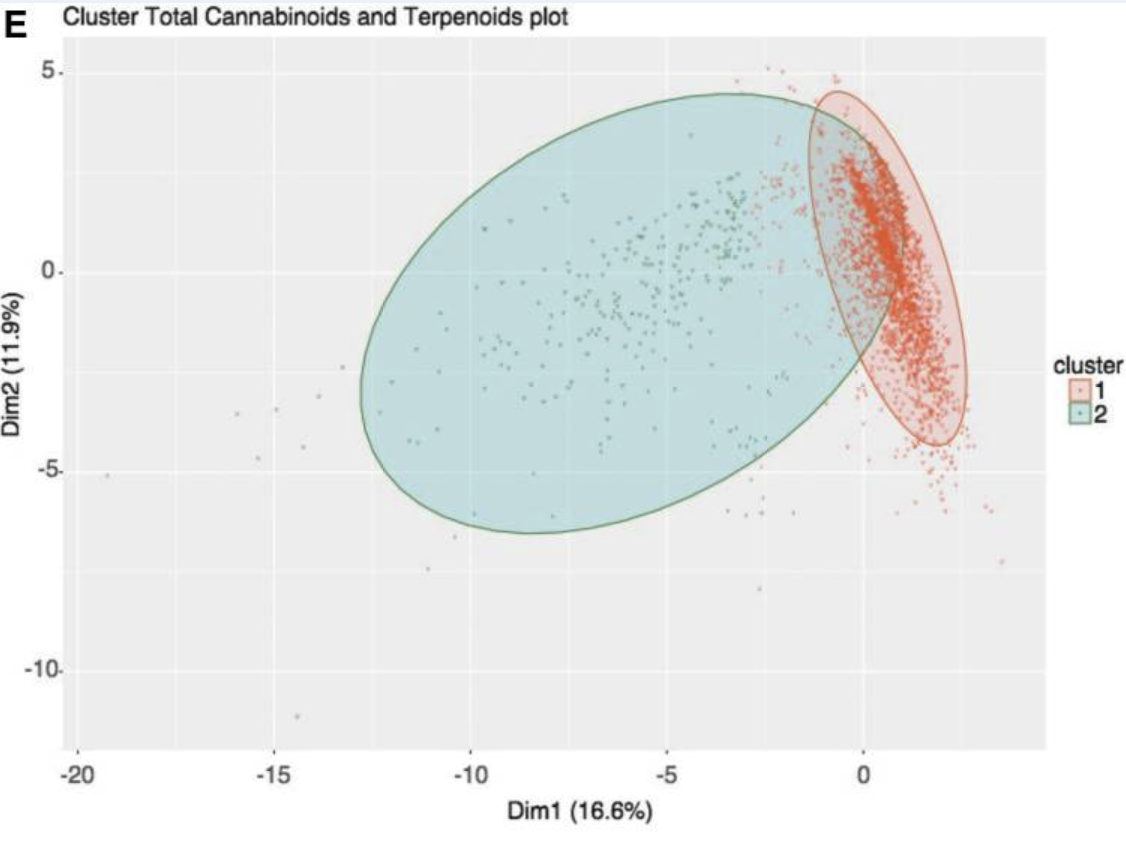 Cannabis Analysis: Understanding Strain Names through NLP(advisor) Christiane Fellbaum, (advisor) Jérémie Lumbroso, and Henrique Schechter Vera2022
Cannabis Analysis: Understanding Strain Names through NLP(advisor) Christiane Fellbaum, (advisor) Jérémie Lumbroso, and Henrique Schechter Vera2022We create and publish the largest public cannabis strain dataset and draw methods from NLP (sentiment analysis, word embeddings) and statistics to find patterns in strain names using strains’ ratings, effects, flavors, and genealogy. We find that popular strains do not have distinct lexical distributions or sentiment values, strains’ parents account for their popularity, and strains named like their parents actually tend to differ in popularity from their parents.
2021
-
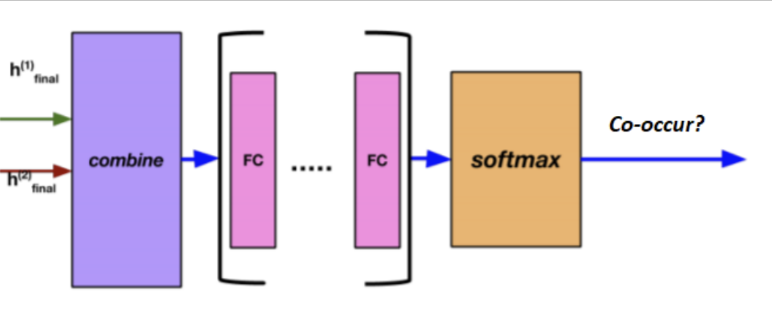 Lyric-Based Automatic Playlist Continuation Using Feature Engineering2021
Lyric-Based Automatic Playlist Continuation Using Feature Engineering2021We develop a novel automatic playlist continuation system. We establish a new method of featurizing songs based on vocabulary, structure, orientation, style, and semantics, which we validate using dimensionality reduction (t-SNE). We then train a neural network to determine a pair of songs’ compatibility using Spotify’s 1M playlist dataset, which we compare to cosine similarity. Our final system was 4x more accurate than our benchmark in both recommending one song and in recommending five songs.